
Uber Maps Tech Talk

Unless you are someone who for some very mystical or other reasons have been living away from technology, you must be very used to what I call the Map Talk - “Can you share the location?”, “Map’s showing a lot of traffic on the way!” etc. Digital and web mapping service has been one area that has continuously evolved and got better with time and technology. Though one of the reasons for that has been the advancements in technology and computation, the other main reason is that it is a very challenging and unsolved problem. And that’s what makes it interesting and that’s what made this Uber Maps Tech Talk very interesting too.
Before two very informative talks we had for the day, there was a video about women in tech in Uber Bangalore’s Engineering team and a trivia which had some swags for those who answered correctly. In case you are wondering, no I haven’t won any! It was Ankit, Group Product Manager for Maps team who gave the first talk. In an earlier talk that happened a few months ago, the presenters explained the number of events and operations that occur between user opening the Uber app and the end of the ride. Locating the rider and driver and providing the accurate route for navigation is very crucial for a smooth ride. Ankit took us through each step, starting with estimation of user location, searching places and addresses, calculating fares and ETA prediction. When a user opens the app, the first thing that’s needed is his/her location. This involves a lot of features to consider like whether the user is indoors or outside, if the user is in a building somewhere above ground level or other such scenarios. This is done using GPS, location prediction models and WiFi fingerprinting. All of this to get that small blue dot at the right place on Uber maps!
There are many factors that should be considered in order to facilitate searching for places or addresses for drop location. The map can use the historical data of the user(if any), show popular places with accurate locations, show a snap of Uber rides that are nearby etc. And when it comes to Uber Eats there are additional different cases that should be considered. The next step which is the fare calculation has to be very accurate. Estimated time of travel, the distance it includes, the presence of tolls, the supply of Uber rides around the current user location and also the demand for rides at the moment are determining factors of estimated fare. If this sounds complex, think about how it can vary for different types of rides — UberGo, UberPool and the more recent ExpressPool. While both UberPool and ExpressPool allow ride sharing, ExpressPool provides a ride from the nearest pickup point which the rider can take by walking to the location. This not only helps the rider to reach a location where rides are available but is also cheaper.
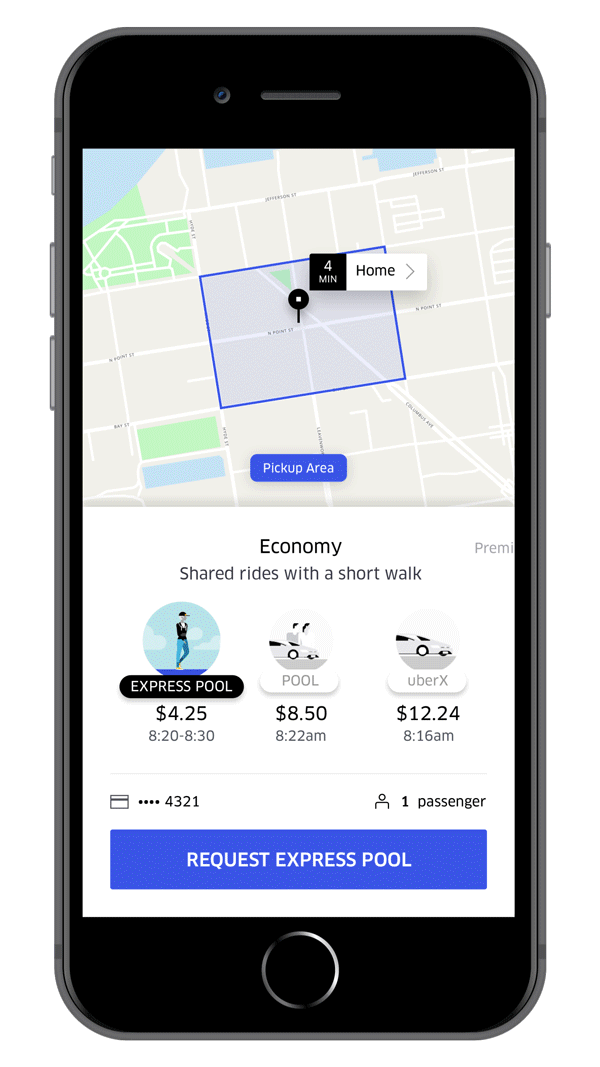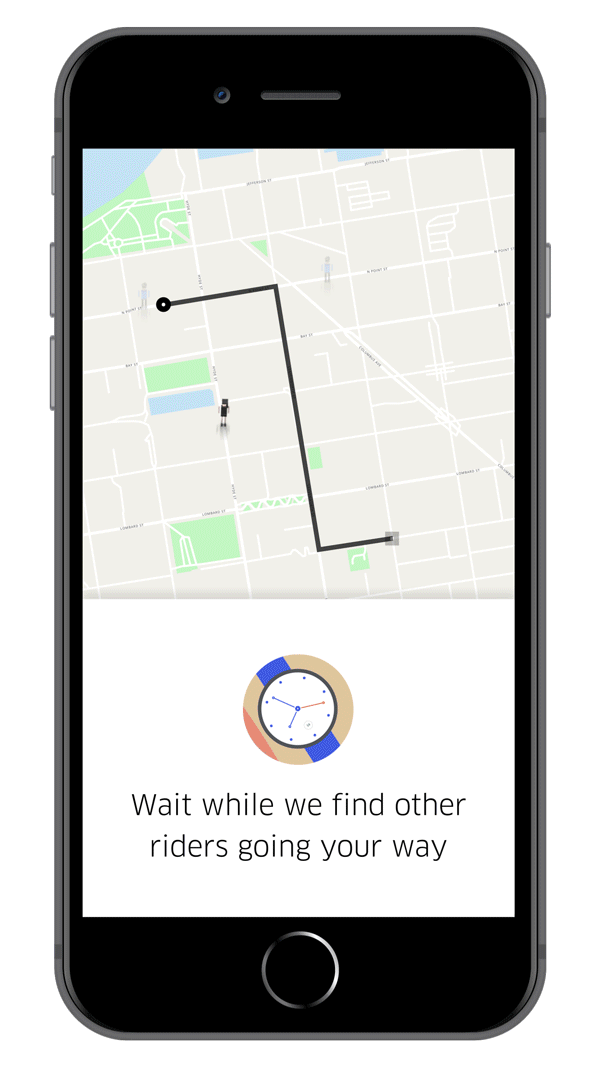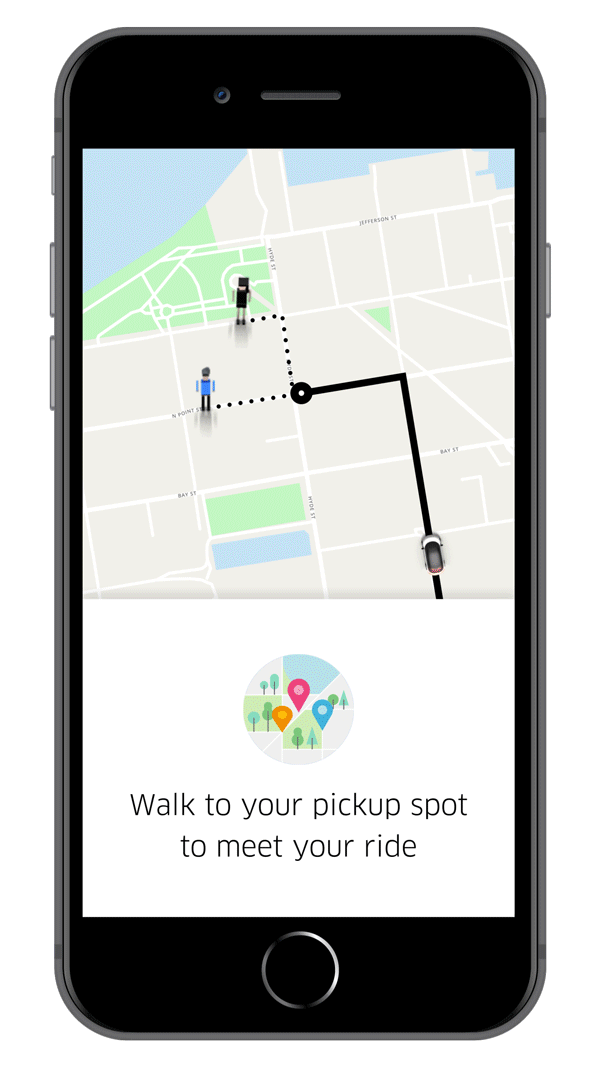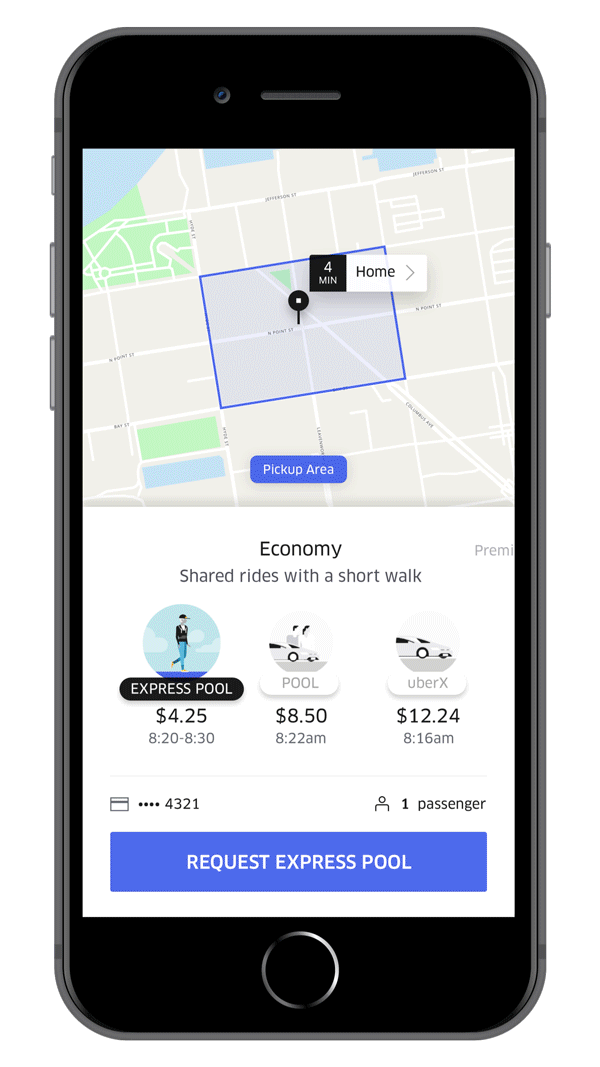
Each step builds from the one before it and has some added layer of complexity. ETA prediction is the next step and it is different for different modes of ride. For UberGo/UberPool, there would be a single ETA of the driver to reach the rider. In case of express pool, the time the rider would take to reach the pickup point should also be considered. ETA calculation has few challenges. What if there is an unforeseen change in traffic? Or a sudden roadblock? What if the driver has a spotty network? The first two lead to recalculation of ETA. To handle spotty networks, the cached routes are reused at the driver side. So even if the driver loses connection, there are ways to make the maps work without it. Once the ride starts, there is continuous route optimisation that happens in the background to assist the driver to take the best possible route to the destination. Historical route records of both the rider and the routes being taken are used for this purpose. Before ending his part of the presentation, Ankit revealed Uber’s plans for multimodal mobility which accommodates rides using different modes that include not just four-wheelers but also bikes, scooters etc.(Just in case you didn’t know, Uber is investing in the scooter renting startup Lime, which is also backed by Google)
“How many of you here have worked on Maps?” asked Gaurang Khetan as he started his talk. There were very few hands raised. So if you want to work on something that is challenging, interesting, has an immediate impact on a popular product, then Maps is all yours. What makes it such a hard and challenging problem? Maps are as good as the data that is collected and good data is hard to get. There are different sources for obtaining data for developing maps and it includes multiple vendors besides others. Maps need to be continuously updated and improved as the physical world keeps changing from time to time. Different countries across the world have different conventions and structures for how they assign addresses. Moreover,it is hard to measure the correctness of maps and the routes. It is not so rare to be lost when following digital maps. Adding to all these reasons, the algorithms used for optimal routing and geo-based search need to be really fast, efficient and scalable.
Map data comes in different layers, from different sources and includes several types like road network, business locations, addresses, physical spaces like malls and buildings, natural features like lakes. The amount of data is not only vast but also very diverse. This makes the quest for global representation using maps a never-ending process. There was another question to the audience,”How can we build the map data for a country or place that doesn’t have any?” You should take a couple of minutes to think and answer it yourself. Postal data, government data, GPS traces, multiple vendors, manually driving and routing, satellite view, crowdsource etc are some of the ways of collecting/creating map data. How much data is enough? With the growing urbanisation and expansion of technology, the urban places must be well mapped and the routes thoroughly understood, right? Though this could be true to some extent, there is one problem that is specific to urban areas — urban canyons.
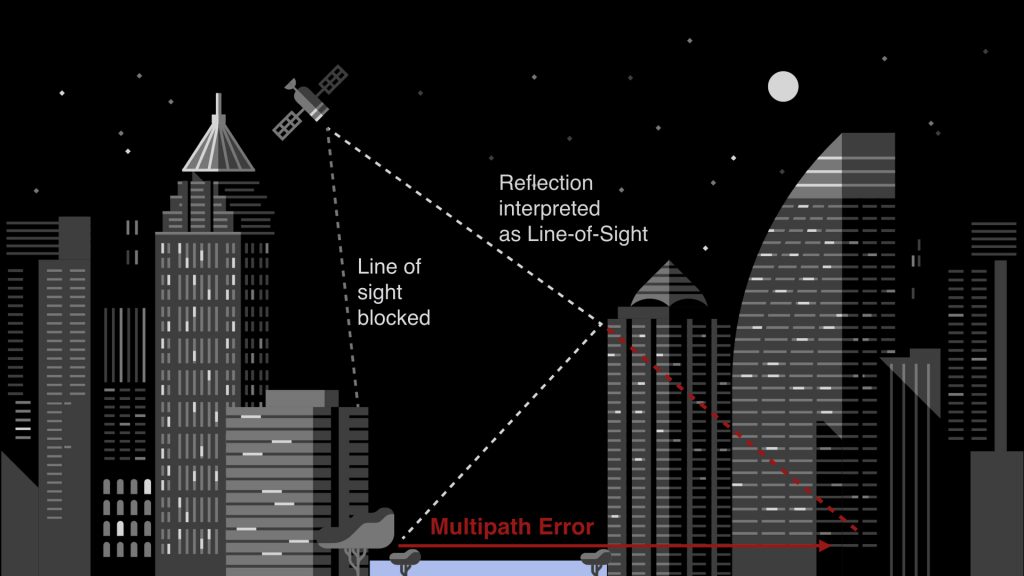
In urban areas or places with high buildings, the satellite signals can get obstructed before directly reaching the GPS receivers. This happens if any high buildings are in the line of sight to satellites. To quickly sum it up, GPS uses many satellites(30 or more) that revolve around Earth’s orbit and transmit signals that are used by GPS receivers for location identification. These signals can be blocked or reflected by the buildings that exist in their way of propagation. And when this happens, it causes an error in location information. This error varies from a few metres to 50m or more. The above image is one such example.
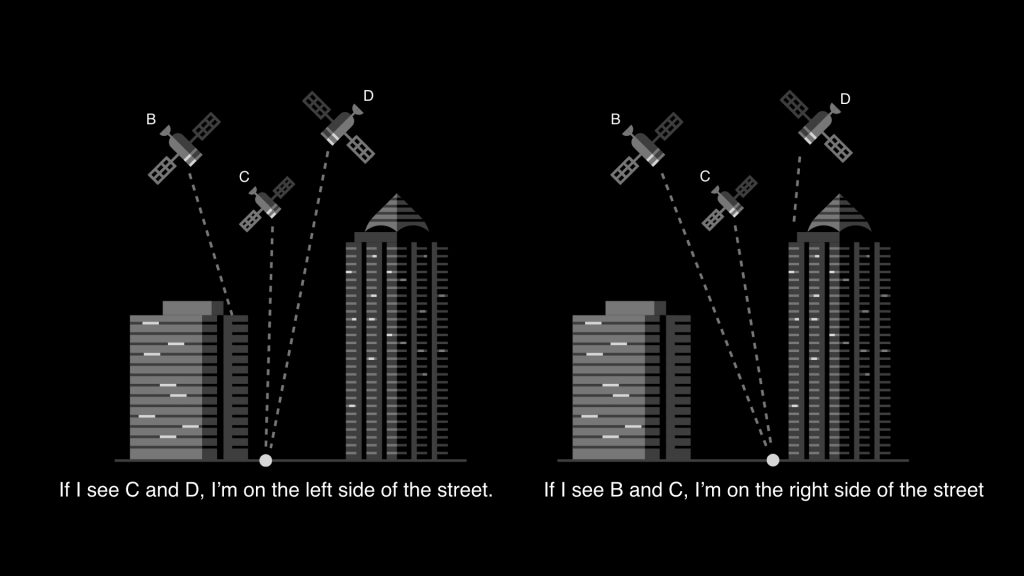
To overcome this problem, Uber Maps use Signal to Noise Ratio(SNR). If for a satellite the SNR value is low, that means there is no direct line of sight to the corresponding satellite and there will be some error in location information. When it’s high, there must be a clear line of sight to satellite and hence the location information will be accurate. In the above picture, we can see that the point on left, is in line of sight to satellites C and D but not to B. Similarly, the point on right is in direct line of sight to satellites B and C but not D. This information can be very useful and the same can also be used to determine whether the location lies on left or right side of the road.
As it is clear, there is so much to know, learn, try and improve when it comes to Maps and that’s what Uber is doing. It doesn’t simply use Google Maps and work on the raw information that GPS provides. Maps is an active research area at Uber and they are continuously making it better. As an example to understand how Uber makes the location information better, see the below comparison between the location information that raw GPS provides(the one in red) and that of Uber’s improved GPS(in blue). While improved GPS provides better navigation, raw GPS is going all over the route.

This is the third Uber Tech Talk I attended this year and the talks were really interesting. Though it is well known that maps and graphs are not easy to solve problems and are continuously improving, it was really good to know so much about how a company that relies a lot on these areas is currently working and researching on those. We also had a good time networking after the end of talks. The speakers and few others who are currently working in Uber joined us and helped us with the questions and doubts. Thanks to Uber for organising the tech talk.
And they have a cool office by the way!!
If you liked what you read so far in this article and would like to follow what’s all happening at Uber, I recommend checking this blog from Uber and also following @ubereng on Twitter where they tweet about their recent research works and about open source tools.
Here’s the link to the blog I wrote about the first Uber Tech Talk I attended.
Thanks for reading 😄 😄
Leave a Comment